
More than 178,000 GitHub users starred a single markdown file. The file just tells an AI how to behave.
Four rules: Think Before Coding. Simplicity First. Surgical Changes. Goal-Driven Execution. That's it. No library. No framework. No installer. Forrest Chang packaged Andrej Karpathy's observations about LLM coding failure modes into a single CLAUDE.md file, and the developer community pushed it past 178,000 GitHub stars in the months that followed.
If you squint at what happened there, it looks a lot like what every engineering organization figured out it needed, eventually, after enough pain: a shared set of constraints on how code gets written. A rules layer. The kind of thing that used to live in a code review checklist, or a style guide, or a senior engineer's institutional memory. The vibe coding community found a much lighter version of that same discipline: write the rules down in markdown and let the agent read them before it writes code.
This is not a one-off. It's a pattern.
TL;DR
- The agent-instruction ecosystem (CLAUDE.md, AGENTS.md, shared skills libraries, and accessibility agents) is becoming a distributed quality enforcement layer for AI-assisted coding.
- The quality gap it's responding to is real: Snyk scanned 3,984 skills from ClawHub and skills.sh and found that 1,467, or 36.82%, had at least one security flaw; 534, or 13.4%, had at least one critical-level issue.
- The community's response has been to build more rules, not abandon the approach, and institutions from Vercel to OWASP to the Linux Foundation are now involved.
The Quality Gap Is Real, and the Community Knows It

13.4% of community skills files contain critical security flaws. That's from Snyk's ToxicSkills report, published February 2026 after scanning 3,984 skills from ClawHub and skills.sh. 36.82% had at least one security vulnerability. 76 were outright malicious, with 91% of those using prompt injection as the delivery mechanism.
The broader AI code quality story is similar. According to CodeRabbit's analysis of code review data, AI-assisted code averages 10.83 issues per pull request versus 6.45 for human-written code, roughly 1.7x more issues. GitClear's annual code study reported what it calls "4x growth" in code cloning: a rise from 8.3% to 12.3% of changed lines between 2021 and 2024.
These are vendor numbers, so take the precision with appropriate skepticism. Still, they are directionally useful: AI-assisted coding is creating enough quality pressure that developers are building new guardrails around it.
What matters is what the community did with this information. The response was not "skills files are dangerous, stop using them." It was: OWASP launched the Agentic Skills Top 10 (AST10), the skills-ecosystem equivalent of the Web Application Security Top 10. More rules. More structure. A formal security framework for an informal ecosystem.
That is a classic engineering response, even from a community that often tries to avoid heavyweight process.
The Ecosystem That Appeared

Over the first half of 2026, this started to look less like a handful of isolated markdown files and more like a layered ecosystem.
Start with the behavioral layer. The Karpathy-inspired CLAUDE.md packages Forrest Chang's version of Andrej Karpathy's LLM coding-failure observations into a single instruction file, and it now sits at more than 178,000 GitHub stars, one of the most starred repositories in GitHub history, for a file built around four simple rules. What those rules are is less interesting than what they represent: an attempt to encode the judgment a senior engineer would apply during code review.
Above that sits a community aggregation layer. Antigravity Awesome Skills has crossed 1,595+ agentic skills, collecting reusable playbooks for Claude Code, Cursor, Codex CLI, Gemini CLI, Antigravity, and other AI coding assistants. It functions like a fast-moving shared library for the space: the kind of thing a standards committee might produce if it moved through GitHub instead of PDFs.
Then the frameworks showed up. Vercel made vercel-labs/agent-skills an official organization repository, now at 28,000 stars. The React Best Practices skill alone contains 40+ rules across eight performance-focused categories, including waterfalls, bundle size, server-side performance, client-side data fetching, re-render optimization, rendering performance, and JavaScript micro-optimizations. When the company that owns your deployment platform ships official quality rules for AI agents, the ecosystem has graduated from community experiment to production infrastructure.
And at the top, a standards layer. OpenAI donated the AGENTS.md specification to the Linux Foundation's Agentic AI Foundation (AAIF) alongside MCP (Anthropic) and Goose (Block): cross-tool, cross-agent, standards-track. The direction is toward portability: AGENTS.md gives teams a shared place for project-specific agent guidance, even though individual tools may still differ in how they load and apply those instructions.
These pieces did not appear as one centrally planned stack. They converged because the demand was real.
The Dimension Nobody Is Talking About
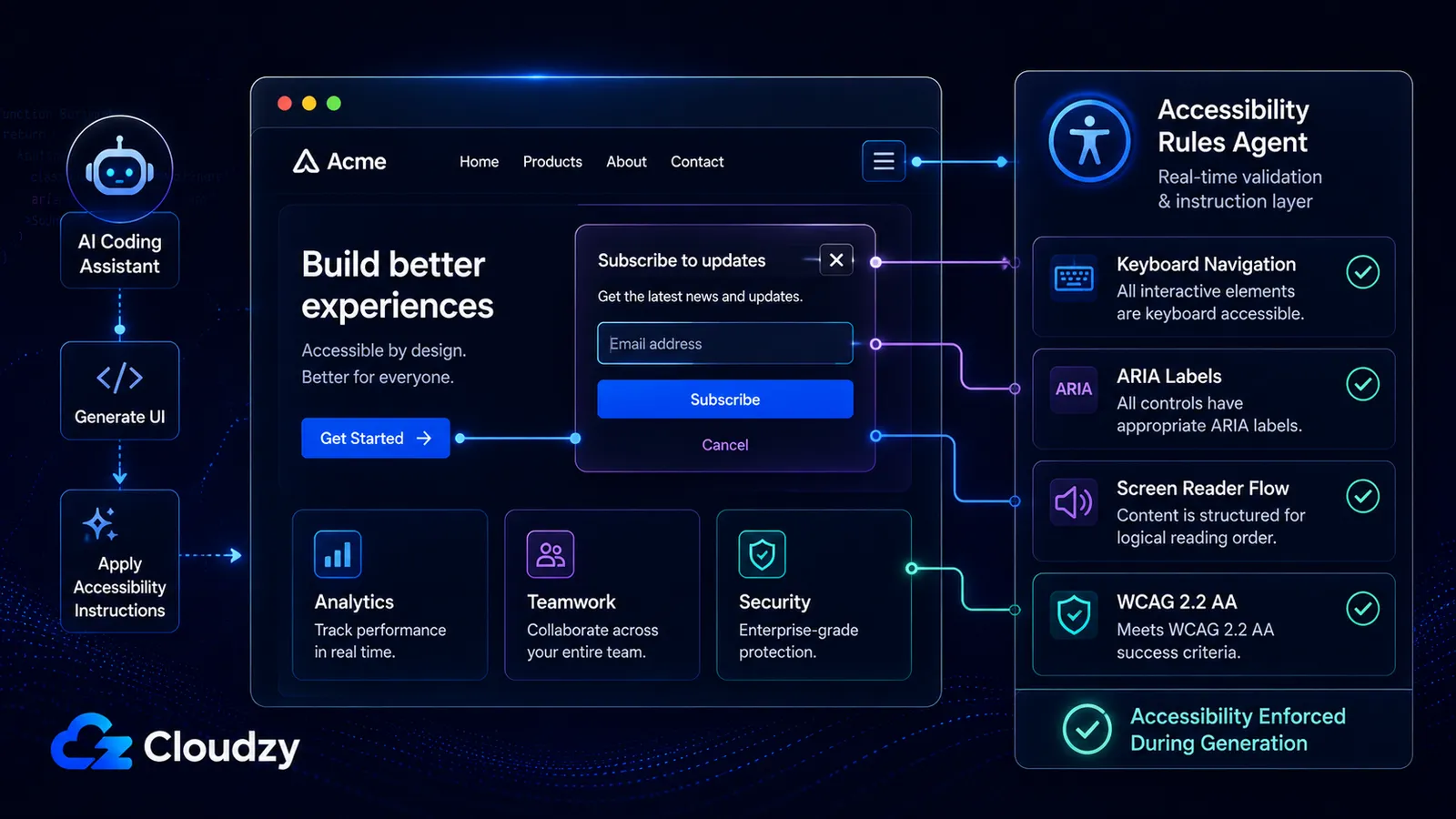
The security and code quality data gets coverage. The accessibility dimension almost never does.
Community-Access/accessibility-agents started on February 21, 2026 with six agents. As of June 2026: 79 specialized agents across eight teams, 18 reusable accessibility skills, WCAG 2.2 AA targeting, and support across five platforms: Claude Code, GitHub Copilot, Gemini CLI, Codex CLI, and an MCP Server that can serve MCP-compatible clients.
What this project is, in plain terms: a community of developers decided that AI coding tools generate inaccessible code by default (they skip ARIA rules, ignore keyboard navigation, produce modals that trap screen readers) and built 79 specialized agents to enforce the rules the AI keeps forgetting.
That's a remarkable thing to happen. Frontend engineers have historically under-delivered on accessibility. It's the first thing cut under deadline pressure. The accessibility-agents project is vibe coders writing the rules they'd otherwise need a senior engineer to enforce, and doing it in public, for free, across five supported integrations.
In my reading, the project is unusually thorough for a volunteer accessibility effort, especially because it turns accessibility from a late QA concern into reusable agent instructions that run during code generation.
Why This Was Inevitable
The argument that "skills files are just READMEs for AI" is fair if you're looking at any one file. It stops holding when you look at OWASP launching a security framework for the ecosystem, Vercel shipping an official quality library, or a volunteer accessibility project growing into 79 specialized agents.
Here's what's actually happening: quality enforcement doesn't disappear when you remove process. It reappears in a different form, because the absence of quality produces pain fast, and the person closest to that pain fixes it at the source.
Traditional engineering discipline (code review, style guides, QA gates, architectural governance) exists to catch what individual developers skip under time pressure. It works when you have a team and a process. Vibe coders, by design, often have neither. So they pre-encoded the review in the agent's instructions.
CLAUDE.md is pre-encoded code review. Awesome Skills is a distributed style guide. AGENTS.md is a governance standard. The words changed. The function didn't.
What's interesting is not that the constraints reappeared, that was inevitable. What's interesting is that they reappeared faster than they did the first time, and more publicly, and at a quality level that embarrasses some engineering organizations with mature processes.
The vibe coding community didn't reinvent engineering discipline reluctantly, under pressure from management. They built it because they hit a wall and the tools to fix it were a markdown file away.
Frequently Asked Questions
What Goes into a CLAUDE.md File?
Behavioral constraints for the AI: what to avoid, what to prioritize, architectural rules, security red flags, and project-specific conventions. Quality-focused usage goes beyond workflow shortcuts: rules like "never remove error handling to make tests pass" sit alongside "always use TypeScript." For real, tested examples, start with the Awesome Skills community aggregation. Vercel's agent-skills is another strong reference.
What Is AGENTS.md and How Is It Different from CLAUDE.md?
AGENTS.md is a universal standard for project-specific agent guidance, released by OpenAI and contributed to the Linux Foundation's Agentic AI Foundation in December 2025. CLAUDE.md is Claude Code's project guidance file. They overlap in purpose, but they are not identical formats in every tool. The practical takeaway is that teams can increasingly write agent instructions once and adapt them across tools such as Codex, Cursor, Copilot, Gemini CLI, and Claude Code.
Are Skills Files Secure to Use?
Community-sourced skills should be read before importing. Snyk's ToxicSkills report found that 36% of scanned community skills had at least one security flaw, and 13.4% had critical-level flaws, with prompt injection as the primary attack mechanism. The OWASP Agentic Skills Top 10 is the reference framework for understanding the attack surface. Skills files from official repositories or established open-source projects generally carry lower supply-chain risk than anonymous community contributions, but they should still be reviewed before import.
What Is the OWASP Agentic Skills Top 10 (AST10)?
OWASP's 2026 security framework for the skills ecosystem, analogous to the OWASP Web Application Security Top 10 but specifically addressing the attack surface created by AI agent instruction files. It covers the ten most critical security risks across platforms including Claude Code, Cursor/Codex, and VS Code. The framework is in active development as of 2026, with a v1.0 release planned for Q4 2026.
Do I Need Skills Files If I'm Building a Personal Project?
Only if you want consistent AI behavior. Without constraints, AI coding tools optimize for task completion, not code quality, which works fine until it produces duplicated logic, missing error handling, or inaccessible UI components. The overhead is low: one file per project, maintained as you discover what the AI keeps getting wrong. The Karpathy-inspired rules are a reasonable starting point; the community skills libraries let you pull in domain-specific rules (security, accessibility, language idioms) without writing them from scratch.


